Hola, bienvenidos al blog, en esta ocasión les traigo algo «nuevo», está bien, no es nuevo pero si es interesante. Vamos a hablar de PNL, el cuál es un tema muy interesante. involucra muchísimas cosas y aqui vamos a tratar especificamente de un cosa; El texto.
Así es, como lo dice el título del post hoy vamos a aprender un poco de Tokenizing que no es más que dividir algo en una lista de algo.
Tokenizing
Conceptualmente es la división de texto o cadenas de texto en partes más pequeñas como frases, palabras o símbolos, utilizando así un concepto como el de «divide y vencerás«. El resultado de hacer el Tokenizing será una lista de Tokens.
Por ejemplo, si aplicamos el Tokenizing a un párrafo el resultado será una lista de tokens los cuales estarán compuestos de oraciones, si hacemos lo mismo pero para una oración obtendremos una lista de tokens compuestos por las palabras que componen dicha oración.
Teniendo la siguiente oración podemos ver que al hacer el Tokenizing obtendremos dos tokens, el de color azul y el de color naranja. Estos a su vez puedes ser separados en palabras pero para el ejmeplo utilizaremos primero la separación por sentencias.

Text Tokenizing
Python y NLTK
Hacer el Tokenizing en python es ralmente sencillo, y si programar algoritmos en python es fácil, utilizando librerías como NLTK es aún más sencillo.
Crearemos un nuevo archivo de script python o desde la consola puedes trabajar.
from nltk.tokenize import sent_tokenize para = "Today is good to see you. How are you?" print sent_tokenize(para)
En el código de python importamos la librería NLTK y en concreto la parte de Tokenize el cuál nos ayudará con la creación de tokens.
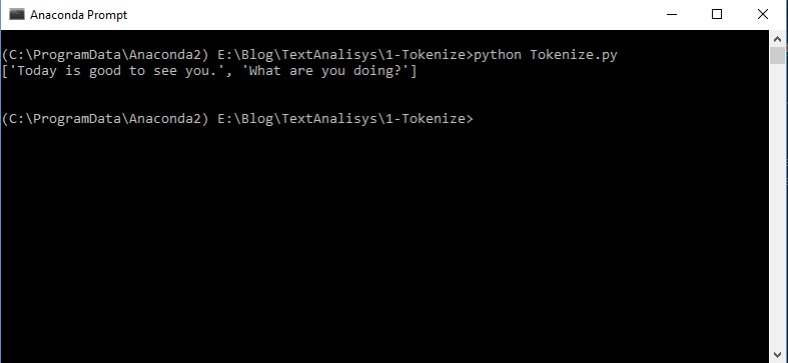
Con esto podemos empezar a probar la magia de la librería. Con una cadena vamos a realizar el tokenizing, para este ejemplo la cadena es la variable para al final para hacer el tokenizing solamente tenemos que hacer la función sent_tokenize() con la variable como parámetro y en pantalla veremos algo como lo siguiente:
Un vector con token por cada frase será nuestro resultado. sin embargo esta manera resulta no tan efectiva para cuando tenemos un montón de texto, así que ahora vamos a ver una de las maneras más usuales. Utilizar el Tokenize.
Para usar el Tokenize debemos hacer algo un poco similar a lo anterior, solo que con una parte diferente, ahora con NLTK->Data vamos a importarla al script.
import nltk.data
para = "Today is good to see you. How are you?"
tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
print tokenizer.tokenize(para)
Tenemos la misma variable(para) con las sentencias y al ejecutarlo vemos que tenemos el mismo resultado que con la funcion sent_tokenize().
Entonces me dirán que cuál es la diferencia, la pequeña gran diferencia es que para hacer el tokenizing de un monton de sentencias la eficiencia se refleja al utilizar ésta forma.
Una línea diferente es la variable tokenizer la cual es cargada con el lenguaje que se va a utilizar en éste caso es Inglés, pero de igual manera se puede realizar con el español y nos funcionara exactamente igual.
import nltk.data
para = "Hola amigos. Gracias por ver este video. Saludos"
tokenizer = nltk.data.load('tokenizers/punkt/spanish.pickle')
print tokenizer.tokenize(para)
EL resultado de las tres maneras de realizar el tokenizing nos mostrará una pantalla como la siguiente:

Entonces podemos trabajar con un montón de lenguajes (que soporte NLTK obviamente), así terminaremos este sincillo post sobre el tokenizing de oraciones, en el próximo veremos algo más a fondo que sera el tokenizing de frases para que los tokens resultantes sean las palabras de la frase.
Me despido y nos vemos en la siguiente entrada. Cualquier duda o comentario estoy atento y les responderé en breve.
Les dejo ésta canción que tiene buen ritmo y me encantó. Saludos.

2 comentarios sobre “NLTK Tokenizing y Python”